Songbirds stutter, babble when young, become mute if parts of their brains are damaged, learn how to sing from their elders and can even be “bilingual”—in other words, songbirds’ vocalizations share a lot of traits with human speech. However, that similarity goes beyond behavior, researchers have found. Even though humans and birds are separated by millions of years of evolution, the genes that give us our ability to learn speech have much in common with those that lend birds their warble.
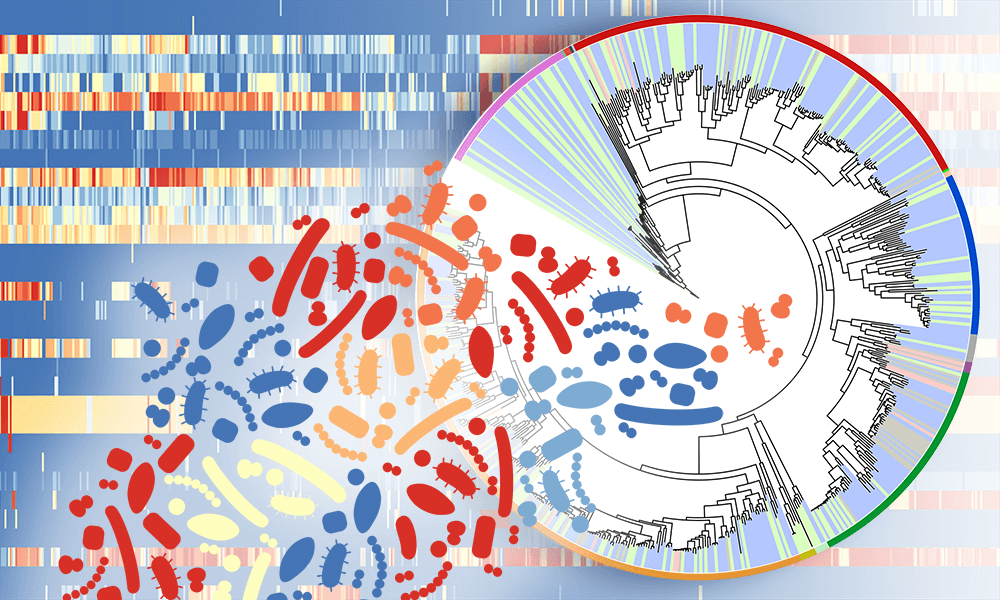
A four-year long effort involving more than 100 researchers around the world put the power of nine supercomputers into analyzing the genomes of 48 species of birds. The results, published this week in a package of eight articles in Science and 20 papers in other journals, provides the most complete picture of the bird family tree thus far. The project has also uncovered genetic signatures in song-learning bird brains that have surprising similarities to the genetics of speech in humans, a finding that could help scientists study human speech.
The analysis suggests that most modern birds arose in an impressive speciation event, a “big bang” of avian diversification, in the 10 million years immediately following the extinction of dinosaurs. This period is more recent than posited in previous genetic analyses, but it lines up with the fossil record. By delving deeper into the rich data set, research groups identified when birds lost their teeth, investigated the relatively slow evolution of crocodiles and outlined the similarities between birds’ and humans’ vocal learning ability, among other findings.
The vocal learning discoveries could have important implications for the study of human speech and its disorders. If the genes are similar, “you can study in song birds and test their function in a way you can’t do in humans,” says Erich Jarvis, one of the leaders of the international effort and an associate professor of neurobiology at Duke University.
Read full, original article: Massive Genetic Effort Confirms Bird Songs Related to Human Speech